TOC
Open TOC
info
https://herbsutter.com/2013/02/11/atomic-weapons-the-c-memory-model-and-modern-hardware/
https://www.youtube.com/watch?v=A8eCGOqgvH4
https://www.youtube.com/watch?v=KeLBd2EJLOU
https://www.bilibili.com/video/BV1vg411y77c
https://colobu.com/2021/06/30/hwmm/
https://colobu.com/2021/07/11/Programming-Language-Memory-Models/
https://paul.pub/cpp-memory-model/
Optimizations, Races, and the Memory Model
在现代 CPU 架构中,多个 CPU 核心共享同一个 RAM,并且它们之间还有 cache 的存在
在下面的讨论中,其基本前提是缓存一致性,可以参考这篇文章
考虑到编译优化,CPU 并不会忠实的按照源代码来执行程序
我们希望 CPU 和编译器能够提供顺序一致性的假象,即每个处理器的操作都是按程序指定的顺序出现的
然而,如果在程序中无法提供足够的信息,这一点就难以做到,因为编译器只了解如下信息
- All memory operations in this thread and exactly what they do, including data dependencies.
- How to be conservative enough in the face of possible aliasing.
编译器并不了解如下信息
- Which memory locations are “mutable shared” variables and could change asynchronously due to memory operations in another thread.
- How to be conservative enough in the face of possible sharing.
因此,我们需要一个契约,而这个契约便是内存模型

更具体的,该模型被称为 sequential consistency for data-race-free programs (SC-DRF)
Ordering – What: Acquire and Release
在代码中经常会出现 Transaction 的需求,例如
bank_account acct1, acct2;// begin transaction – ACQUIRE exclusivityacct1.credit(100);acct2.debit(100);// end transaction – RELEASE exclusivity实现方式有很多,例如
- 使用 lock 保护临界区
- 置 account 为原子变量
- 利用 transactional memory,如
atomic { ... }
lock 的使用会限制编译器的代码移动,例如如下代码
mut_x.lock(); // enter critical region (lock "acquire")x = 42;mut_x.unlock(); // exit critical region (lock "release")不能优化为
x = 42;mut_x.lock(); // enter critical region (lock "acquire")mut_x.unlock(); // exit critical region (lock "release")即不允许 move out
但是 move in 是被允许的
x = "life";mut.lock();y = "universe";mut.unlock();z = "everything";可以优化为
mut.lock();x = "life";y = "universe";z = "everything";mut.unlock();这实际上是一种单向的 barrier
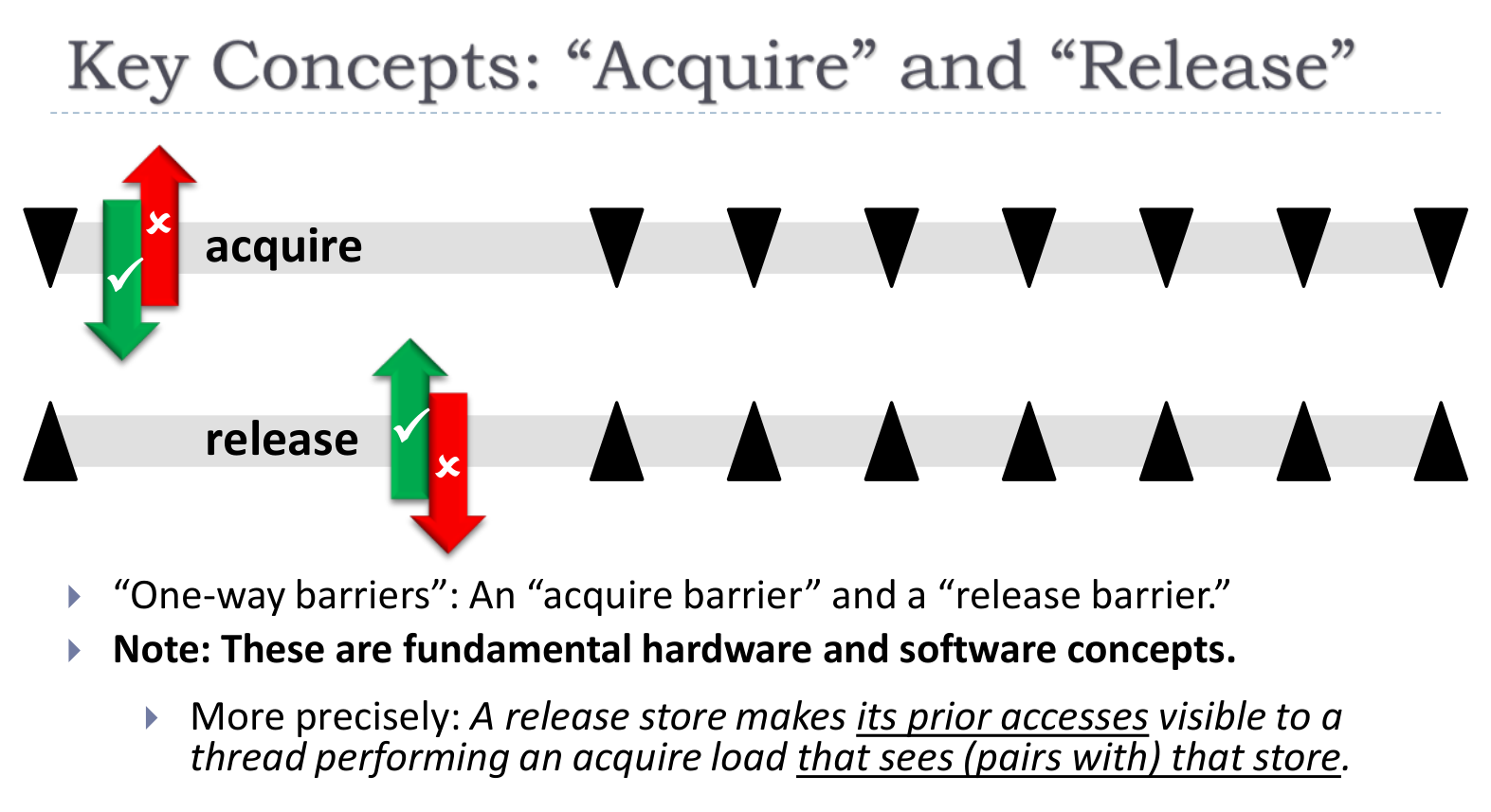
另外,需要注意平凡的 Acq 和 Rel 可能存在重叠,即上面的 Rel 移动到下面的 Acq 后面,这将会导致临界区重叠,所以 SC 的 Acq 和 Rel 是不允许这一点的
Ordering – How: Mutexes, Atomics, and/or Fences
下面考虑原子变量的方式
本质上就是自动 Acquire 和 Release
- read = acquire
- write = release
考虑如下的例子,其中 x 和 y 为原子变量,初值为 0
// thread 1g = 1;x = 1;
// thread 2if (x == 1) y = 1;
// thread 3if (y == 1) assert (g == 1);在 SC-DRF 下,断言一定是成立的,因为 g = 1 一定在 x = 1 之前执行,而 x = 1 才暴露其可见性给其他 thread
使用原子变量还可以实现 lock-free 的并发数据结构,然而通常是很困难的
与其相关的操作是 std::atomic::compare_exchange_weak, std::atomic::compare_exchange_strong
最后考虑 standalone barriers,在 x86 中对应 mfence 指令
不建议使用这种方式,有如下原因
- 可移植性
- 性能开销
- 限制编译优化,例子如下

peterson 算法中 barrier 的使用
#define BARRIER __sync_synchronize()int volatile x = 0, y = 0, turn;
void TA() { while (1) { x = 1; BARRIER; turn = B; BARRIER; // <- this is critcal for x86 while (1) { if (!y) break; BARRIER; if (turn != B) break; BARRIER; } critical_section(); x = 0; BARRIER; }}
void TB() { while (1) { y = 1; BARRIER; turn = A; BARRIER; while (1) { if (!x) break; BARRIER; if (turn != A) break; BARRIER; } critical_section(); y = 0; BARRIER; }}有一些 barrier 是多余的
volatile 将在最后讲解
Other Restrictions on Compilers and Hardware
考虑如下的例子,其中 c 和 d 为全局的 char 类型变量
// Thread 1{ lock_guard<mutex> lock(cMutex); c = 1;}
// Thread 2{ lock_guard<mutex> lock(dMutex); d = 1;}在某些情形下可能会出现数据竞争,例如当 c 和 d 在内存中连续分布时,编译器可以将 d = 1 优化为
char tmp[4]; // 32-bit scratchpadmemcpy(&tmp[0], &c, 4); // read 32 bits starting at ctmp[1] = 1; // set only the bits of dmemcpy(&c, &tmp[0], 4); // write 32 bits back那么 thread 2 将在没有获取 cMutex 的情形下执行 c = c
另一个例子是位域,考虑 s 为类型为 struct { int c:9; int d:7; } 的全局变量
// Thread 1{ lock_guard<mutex> lock(cMutex); s.c = 1;}
// Thread 2{ lock_guard<mutex> lock(dMutex); s.d = 1;}标准规定 adjacent bitfields are one object,所以这必然会出现数据竞争
下面考虑分支预测和寄存器分配带来的问题
一个常见的 pattern 是
if (cond) lock x...if (cond) use x...if (cond) unlock x其中 x 为共享变量,而 cond 是一致的
在 SC-DRF 下,这是安全的,然而,一旦考虑到编译器优化,就会出现问题
例如分支预测
if (cond) x = 42;编译器可以优化为
r1 = x; // read what’s therex = 42; // oops: optimistic write is not conditionalif (!cond) // check if we guessed wrong x = r1; // oops: back-out write is not SC那么就会出现在非条件语句中写入值以及回写的现象
再如寄存器分配
void f(/*...params...*/, bool doOptionalWork) { if (doOptionalWork) xMutex.lock(); for (...) if (doOptionalWork) ++x; // write is conditional if (doOptionalWork) xMutex.unlock();}编译器可以优化为
void f(/*...params...*/, bool doOptionalWork) { r1 = x; for (...) if (doOptionalWork) ++r1; x = r1; // oops: write is not conditional}那么就会出现在非条件语句中写入值的现象
对于这种条件 lock,合理的处理方案有两种
- 拆分包含 doOptionalWork 参数的函数,一个总是持有 lock,一个不持有 lock
- 总是悲观的持有 lock
Code Gen & Performance: x86/x64, IA64, POWER, ARM, …
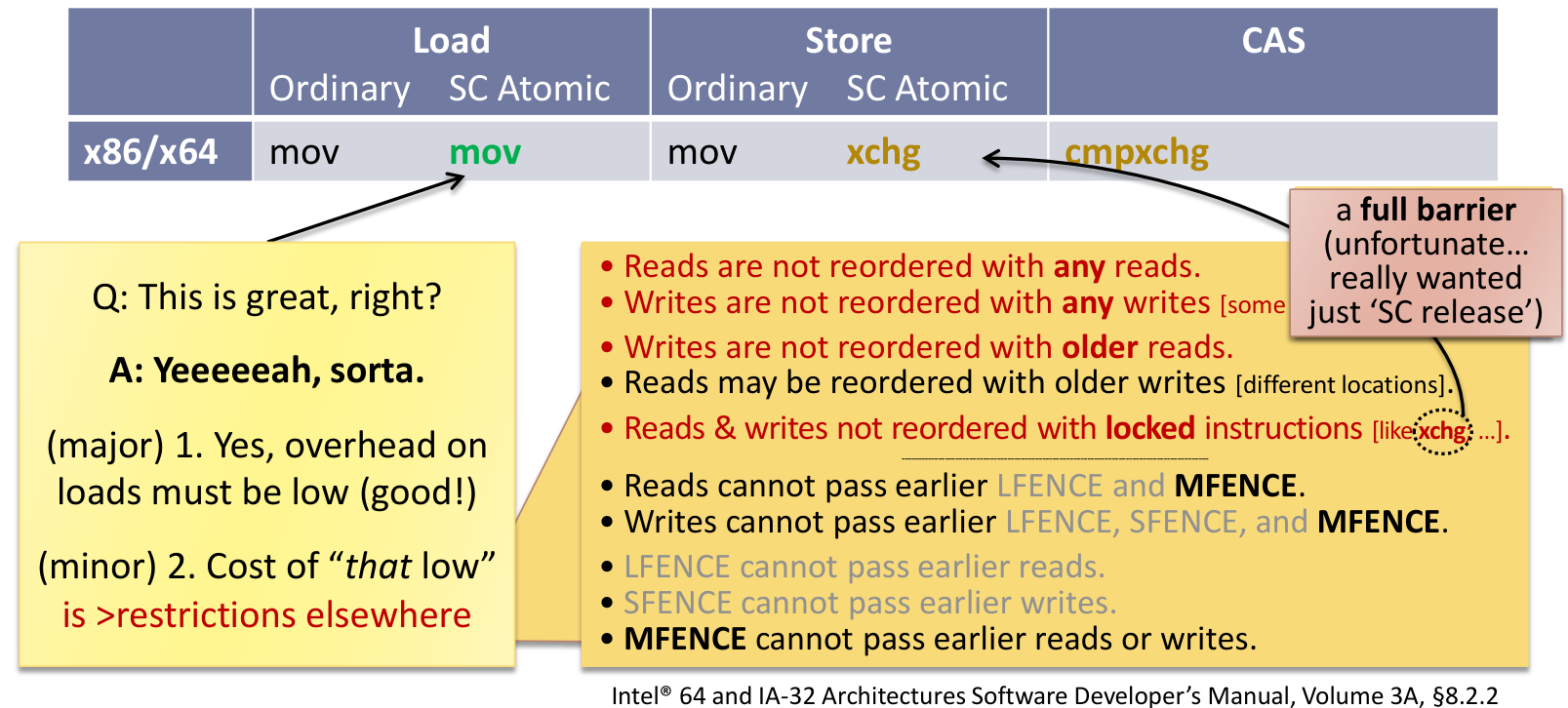
一个常见的优化是,store 可以 expensive,但是 load 一定要 fast
下面是 x86/x64 对应的指令
| Load (Ordinary) | Load (SC Atomic) | Store (Ordinary) | Store (SC Atomic) | CAS | |
|---|---|---|---|---|---|
| x86/x64 | mov | mov | mov | xchg | cmpxchg |
可以发现 SC Atomic 的 Load 和普通的 Load 指令完全相同,这需要付出如下的代价
下面考虑 IA64
| Load (Ordinary) | Load (SC Atomic) | Store (Ordinary) | Store (SC Atomic) | CAS | |
|---|---|---|---|---|---|
| IA64 | ld | ld.acq | st | st.rel; mf | cmpxchg.rel; mf |
注意 store 和 cas 最后的 mf 指令,这是为了避免平凡的 Acq 和 Rel 出现重叠,上面曾经提及过
POWER 架构和 ARM v7 架构分别使用了 sync 和 dmb 指令进行同步,与之而来的是巨大的开销,为此 C11/C++11 提出了 relaxed atomics,以减少性能开销
下面是各个处理器架构对于读写一致性实现的对比
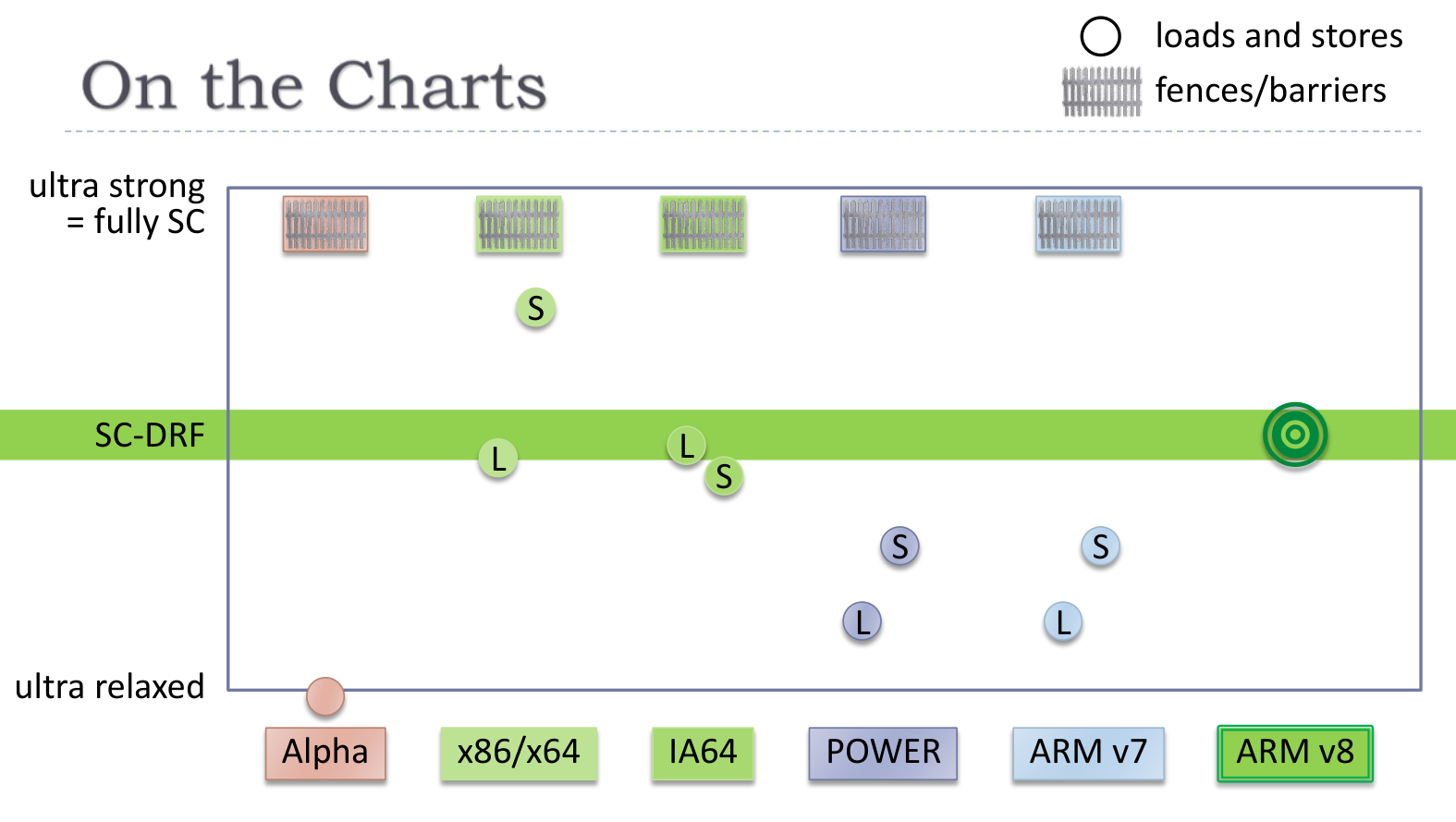
理想的情形是,硬件和软件能够尽可能的在 SC-DRF 达到收敛,以避免不必要的性能开销
Relaxed Atomics
可以稍微放松顺序一致性,以获取更好的性能
Don’t do it.
即使真的需要使用,也应考虑封装的方式,并在文档中注明使用场景
参考 std::memory_order - cppreference.com,下面是几个例子
第一个例子是计数器,其中 count 为全局原子变量
// worker threadswhile (...) { if (...) { ++count; }}
// main threadint main() { launch_workers(); join_workers(); cout << count << endl;}注意到主线程对 count 的访问在所有的 worker 线程结束之后,并且 worker 线程仅仅是自增 count,不存在同步或顺序制约,仅仅要求原子性,那么可以优化为
// worker threadswhile (...) { if (...) { count.fetch_add(1, memory_order_relaxed); }}
// main threadint main() { launch_workers(); join_workers(); cout << count.load(memory_order_relaxed) << endl;}应该封装 count 为某个类的实例,并重载对应的运算符
这实际上是 relaxed 内存模型
第二个例子是引用计数,其中 refs 成员为原子变量
// thread 1control_block_ptr = other->control_block_ptr;++control_block_ptr->refs;
// thread 2if (--control_block_ptr->refs == 0) delete control_block_ptr;对于增加引用计数,分析和上面类似,可以使用 memory_order_relaxed
而减少引用计数,则应使用 memory_order_acq_rel,不使用 memory_order_release 的原因如下

感觉涉及到既读又写,所以既要 acquire,又要 release
这实际上是 acquire release 内存模型
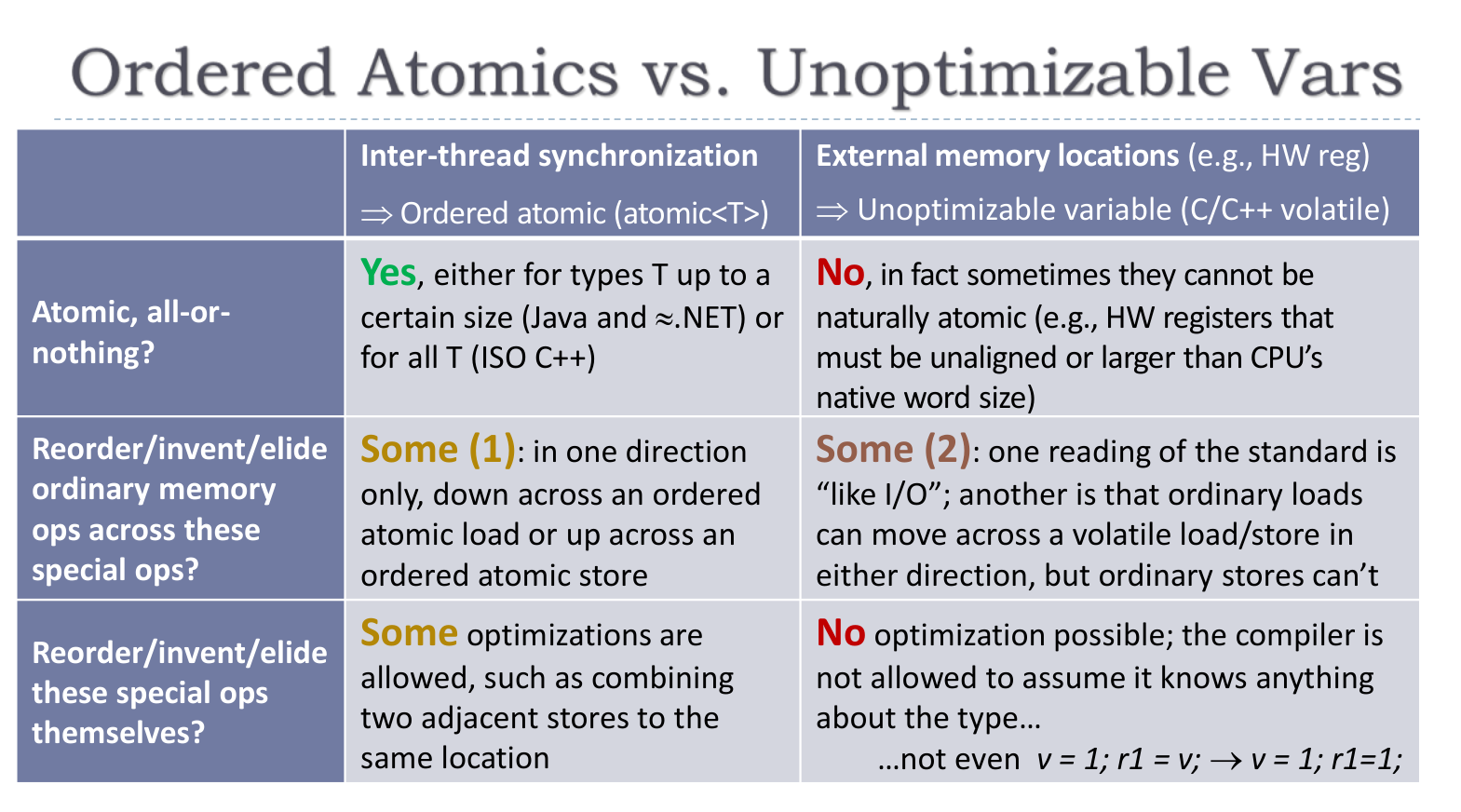
Coda: Volatile
首先需要明确
volatile (Java) != volatile (C, C++)volatile (Java) == atomic (C, C++)
volatile 关键字代表了内存模型之外的东西

可以理解对 volatile 变量的读写为 IO 操作
下面对比了 atomic 和 volatile 变量